seaborn.histplot#
- seaborn.histplot(data=None, *, x=None, y=None, hue=None, weights=None, stat='count', bins='auto', binwidth=None, binrange=None, discrete=None, cumulative=False, common_bins=True, common_norm=True, multiple='layer', element='bars', fill=True, shrink=1, kde=False, kde_kws=None, line_kws=None, thresh=0, pthresh=None, pmax=None, cbar=False, cbar_ax=None, cbar_kws=None, palette=None, hue_order=None, hue_norm=None, color=None, log_scale=None, legend=True, ax=None, **kwargs)#
データセットの分布を示すために、一変量または二変量のヒストグラムをプロットします。
ヒストグラムは、離散的なビンに分類される観測の数を数えることによって、1つ以上の変数の分布を表す古典的な視覚化ツールです。
この関数は、各ビン内で計算された統計量を正規化して、頻度、密度、または確率質量を推定できます。また、
kdeplot()と同様に、カーネル密度推定を使用して得られた滑らかな曲線を追加することもできます。詳細については、ユーザーガイドを参照してください。
- パラメーター:
- data
pandas.DataFrame,numpy.ndarray, マッピング, またはシーケンス 入力データ構造。名前付き変数に割り当てることができるベクトルの長形式コレクション、または内部的にリシェイプされるワイド形式データセットのいずれかです。
- x, y
data内のベクトルまたはキー x軸とy軸の位置を指定する変数。
- hue
data内のベクトルまたはキー プロット要素の色を決定するためにマッピングされるセマンティック変数。
- weights
data内のベクトルまたはキー 指定された場合、各ビンでのカウントに対する対応するデータポイントの寄与をこれらの要因で重み付けします。
- statstr
各ビンで計算する集計統計量。
count: 各ビン内の観測数を表示しますfrequency: 各ビン内の観測数をビン幅で割った値を表示しますprobabilityまたはproportion: バーの高さの合計が1になるように正規化しますpercent: 棒の高さの合計が100になるように正規化します。density: ヒストグラムの総面積が1になるように正規化します。
- bins文字列、数値、ベクトル、またはこれらの値のペア
参照規則の名前、ビンの数、またはビンの区切りとして使用できる一般的なビンパラメータです。
numpy.histogram_bin_edges()に渡されます。- binwidth数値または数値のペア
各ビンの幅です。
binsをオーバーライドしますが、binrangeと組み合わせて使用できます。- binrange数値のペアまたはペアのペア
ビンの端の最小値と最大値です。
binsまたはbinwidthと一緒に使用できます。デフォルトはデータの極値です。- discretebool
Trueの場合、デフォルトで
binwidth=1となり、バーが対応するデータ点の中央に配置されるように描画します。これにより、離散(整数)データを使用する場合に発生する可能性のある「ギャップ」が回避されます。- cumulativebool
Trueの場合、ビンが増加するにつれて累積度数をプロットします。
- common_binsbool
Trueの場合、意味変数によって複数のプロットが生成されるときに、同じビンを使用します。参照規則を使用してビンを決定する場合、完全なデータセットで計算されます。
- common_normbool
Trueで正規化された統計量を使用する場合、正規化は完全なデータセットに適用されます。それ以外の場合は、各ヒストグラムを個別に正規化します。
- multiple{“layer”, “dodge”, “stack”, “fill”}
意味マッピングによってサブセットが作成される場合に、複数の要素を解決する方法です。単変量データの場合のみ関連します。
- element{“bars”, “step”, “poly”}
ヒストグラムの統計量の視覚的な表現です。単変量データの場合のみ関連します。
- fillbool
Trueの場合、ヒストグラムの下のスペースを塗りつぶします。単変量データの場合のみ関連します。
- shrink数値
各バーの幅を、この係数でビン幅を基準にしてスケールします。単変量データの場合のみ関連します。
- kdebool
Trueの場合、カーネル密度推定を計算して分布を平滑化し、(1つまたは複数の)線としてプロット上に表示します。単変量データの場合のみ関連します。
- kde_kwsdict
kdeplot()と同様に、KDE計算を制御するパラメーターです。- line_kwsdict
matplotlib.axes.Axes.plot()に渡される、KDEの視覚化を制御するパラメーターです。- thresh数値またはNone
統計量がこの値以下のセルは透明になります。二変量データの場合のみ関連します。
- pthresh数値またはNone
threshと同様ですが、[0, 1]の値であり、合計に対するこの割合までの集計数(または使用時は他の統計量)を持つセルが透明になります。- pmax数値またはNone
[0, 1]の値であり、合計カウント(または使用時は他の統計量)のこの割合を構成するセルが、カラーマップの彩度ポイントを設定します。
- cbarbool
Trueの場合、二変量プロットでカラーマッピングを注釈するためにカラーバーを追加します。注:現在、
hue変数を伴うプロットは十分にサポートされていません。- cbar_ax
matplotlib.axes.Axes カラーバーの既存の軸。
- cbar_kwsdict
matplotlib.figure.Figure.colorbar()に渡される追加のパラメーターです。- palette文字列、リスト、辞書、または
matplotlib.colors.Colormap hueセマンティックをマッピングする際に使用する色を選択する方法です。文字列値は、color_palette()に渡されます。リストまたは辞書の値はカテゴリカルマッピングを意味し、カラーマップオブジェクトは数値マッピングを意味します。- hue_order文字列のベクトル
hueセマンティックのカテゴリカルレベルの処理とプロットの順序を指定します。- hue_normタプルまたは
matplotlib.colors.Normalize データ単位で正規化範囲を設定する値のペア、またはデータ単位から[0, 1]の間隔にマッピングするオブジェクトです。使用は数値マッピングを意味します。
- color
matplotlib color 色相マッピングが使用されない場合の単一の色指定です。それ以外の場合、プロットはmatplotlibプロパティサイクルにフックしようとします。
- log_scaleboolまたは数値、またはboolまたは数値のペア
軸のスケールをログに設定します。単一の値は、プロット内の任意の数値軸のデータ軸を設定します。値のペアは、各軸を個別に設定します。数値は、希望のベース(デフォルトは10)として解釈されます。
NoneまたはFalseの場合、seabornは既存の軸のスケールに従います。- legendbool
Falseの場合、セマンティック変数の凡例を抑制します。
- ax
matplotlib.axes.Axes プロットの既存の軸。それ以外の場合は、内部で
matplotlib.pyplot.gca()を呼び出します。- kwargs
その他のキーワード引数は、次のmatplotlib関数のいずれかに渡されます
matplotlib.axes.Axes.bar()(単変量、element = "bars")matplotlib.axes.Axes.fill_between()(単変量、その他の要素、fill = True)matplotlib.axes.Axes.plot()(単変量、その他の要素、fill = False)
- data
- 戻り値:
matplotlib.axes.Axesプロットを含むmatplotlib軸。
参考
注記
ヒストグラムを計算およびプロットするためのビンの選択は、視覚化から得られる洞察に大きな影響を与える可能性があります。ビンが大きすぎると、重要な機能が消去される可能性があります。一方、ビンが小さすぎると、ランダムな変動に支配され、真の基礎となる分布の形状が不明瞭になる可能性があります。デフォルトのビンサイズは、サンプルサイズと分散に依存する参照規則を使用して決定されます。これは多くの場合(つまり、「適切な」データの場合)はうまく機能しますが、そうでない場合もあります。何か重要なものを見逃していないことを確認するために、さまざまなビンサイズを試してみることをお勧めします。この関数を使用すると、使用するビンの総数、各ビンの幅、またはビンが分割される特定の場所を設定するなど、いくつかの異なる方法でビンを指定できます。
例
xに変数を割り当てて、x軸に沿って単変量分布をプロットしますpenguins = sns.load_dataset("penguins") sns.histplot(data=penguins, x="flipper_length_mm")

データ変数をy軸に割り当てることで、プロットを反転させます
sns.histplot(data=penguins, y="flipper_length_mm")

異なるビン幅を指定して、ヒストグラムがデータをどれだけ適切に表現しているかを確認します
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)

使用するビンの総数を定義することもできます
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)

カーネル密度推定を追加して、ヒストグラムを平滑化し、分布の形状に関する補足情報を提供します
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)

xもyも割り当てられていない場合、データセットはワイド形式として扱われ、数値列ごとにヒストグラムが描画されますsns.histplot(data=penguins)

それ以外の場合は、色相マッピングを使用して、ロング形式のデータセットから複数のヒストグラムを描画できます
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")

複数の分布をプロットするデフォルトのアプローチは、それらを「レイヤー」することですが、「スタック」することもできます
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")

重複するバーは視覚的に解決するのが難しい場合があります。別のアプローチは、ステップ関数を描画することです
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")

各ビンの中心に頂点を持つ多角形を描画することで、バーからさらに離れることができます。これにより、分布の形状を把握しやすくなる可能性がありますが、注意して使用してください。ヒストグラムを見ていることが、視聴者には分かりにくくなります
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")

サイズが大幅に異なるサブセットの分布を比較するには、独立した密度正規化を使用します
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False, )
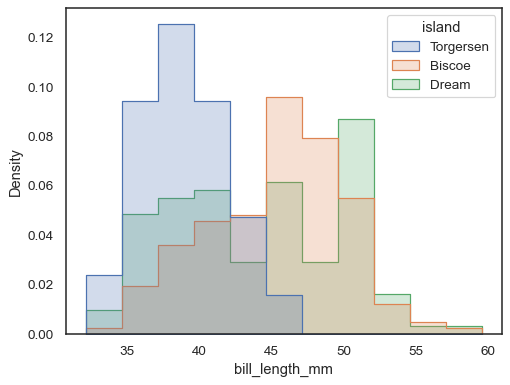
また、各バーの高さが確率、割合、またはパーセントを示すように正規化することもできます。これは離散変数ではより理にかなっています
tips = sns.load_dataset("tips") sns.histplot(data=tips, x="size", stat="percent", discrete=True)

カテゴリ変数に対してヒストグラムを描画することもできます(ただし、これは実験的な機能です)。
sns.histplot(data=tips, x="day", shrink=.8)

hueセマンティックを離散データで使用する場合、レベルを「ドッジ」することが理にかなう場合があります。sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)

現実世界のデータはしばしば歪んでいます。大きく歪んだ分布の場合、ビンを対数空間で定義する方が適切です。以下を比較してください。
planets = sns.load_dataset("planets") sns.histplot(data=planets, x="distance")

対数スケール版と比較してください。
sns.histplot(data=planets, x="distance", log_scale=True)

ヒストグラムの表示方法には、いくつかのオプションもあります。塗りつぶされていないバーを表示できます。
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)

または、塗りつぶされていないステップ関数を表示できます。
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)

ステップ関数、特に塗りつぶされていない場合は、累積ヒストグラムを簡単に比較できます。
sns.histplot( data=planets, x="distance", hue="method", hue_order=["Radial Velocity", "Transit"], log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False, )

xとyの両方が割り当てられている場合、二変量ヒストグラムが計算され、ヒートマップとして表示されます。sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")

hue変数も割り当てることができますが、異なるレベルのデータに大きな重複がある場合は、うまく機能しません。sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")

変数の1つが離散的である場合、複数のカラーマップが適切になる場合があります。
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False )

二変量ヒストグラムは、一変量の場合と同じ計算オプションをすべて受け入れ、
xとyを個別にパラメータ化するためにタプルを使用します。sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), )
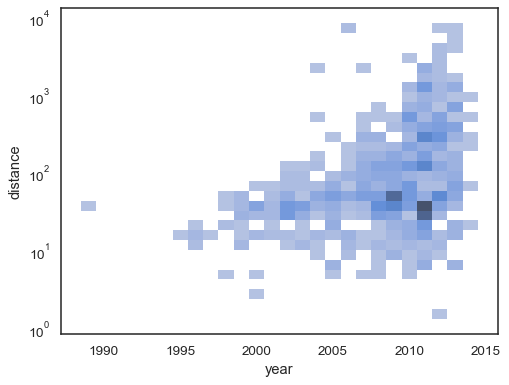
デフォルトの動作では、観測値がないセルは透明になりますが、これは無効にできます。
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None, )

累積カウントの割合に基づいて、しきい値とカラーマップの彩度点を設定することもできます。
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9, )

カラーマップに注釈を付けるには、カラーバーを追加します。
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75), )
