seaborn.objects.KDE#
- class seaborn.objects.KDE(bw_adjust=1, bw_method='scott', common_norm=True, common_grid=True, gridsize=200, cut=3, cumulative=False)#
単変量カーネル密度推定を計算します。
- パラメータ:
- bw_adjust浮動小数点数
bw_methodを使用して選択された値を乗算的にスケーリングする係数。値を大きくすると曲線が滑らかになります。備考を参照してください。- bw_method文字列、スカラー、または呼び出し可能オブジェクト
使用する平滑化帯域幅を決定するためのメソッド。
scipy.stats.gaussian_kdeに直接渡されます。オプションについてはそちらを参照してください。- common_normブール値または変数のリスト
Trueの場合、すべての曲線の面積の合計が1になるように正規化します。Falseの場合、各曲線を個別に正規化します。リストの場合、グループ化して正規化する変数を定義します。- common_gridブール値または変数のリスト
Trueの場合、すべての曲線が同じ評価グリッドを共有します。Falseの場合、各評価グリッドは独立しています。リストの場合、グループ化してグリッドを共有する変数を定義します。- gridsize整数またはNone
評価グリッド内の点の数。Noneの場合、密度は元のデータポイントで評価されます。
- cut浮動小数点数
カーネル帯域幅に乗算される係数。評価グリッドが極値データポイントを超えてどのくらい延びるかを決定します。0に設定すると、曲線はデータの制限で切り捨てられます。
- cumulativeブール値
Trueの場合、累積分布関数を推定します。scipyが必要です。
備考
帯域幅、つまり平滑化カーネルの標準偏差は重要なパラメータです。ヒストグラムのビン幅と同様に、間違った帯域幅を使用すると、歪んだ表現になる可能性があります。過剰な平滑化は真の特徴を消去する可能性があり、平滑化が不十分だと偽の特徴を作成する可能性があります。デフォルトでは、おおよそベル型の分布に最適な経験則を使用しています。
bw_adjustを変更してデフォルトを確認することをお勧めします。平滑化はガウスカーネルを使用して実行されるため、推定密度曲線は意味のない値にまで拡張される可能性があります。たとえば、データが本質的に正である場合、曲線が負の値に描画される可能性があります。
cutパラメータを使用して評価範囲を制御できますが、自然な境界に近い観測値が多いデータセットは、別の方法で処理する方が良い場合があります。データセットが本質的に離散的または「スパイク状」(同じ値の繰り返し観測値が多い)の場合、同様の歪みが発生する可能性があります。KDEは常に滑らかな曲線を生成しますが、これは誤解を招く可能性があります。
密度軸の単位は混乱の原因となることがよくあります。カーネル密度推定は確率分布を生成しますが、各点における曲線の高さは確率ではなく密度を示します。確率は、密度を範囲全体にわたって積分することによってのみ得られます。曲線は、すべての可能な値の積分が1になるように正規化されます。つまり、密度軸のスケールはデータ値に依存します。
scipyがインストールされている場合、そのcythonで高速化された実装が使用されます。
例
この統計量は、観測値を推定密度を表す滑らかな関数に変換します
p = so.Plot(penguins, x="flipper_length_mm") p.add(so.Area(), so.KDE())

平滑化帯域幅を調整して、詳細の表示/非表示を切り替えます
p.add(so.Area(), so.KDE(bw_adjust=0.25))

曲線はデータセット内の観測値を超えて延長されます
p2 = p.add(so.Bars(alpha=.3), so.Hist("density")) p2.add(so.Line(), so.KDE())
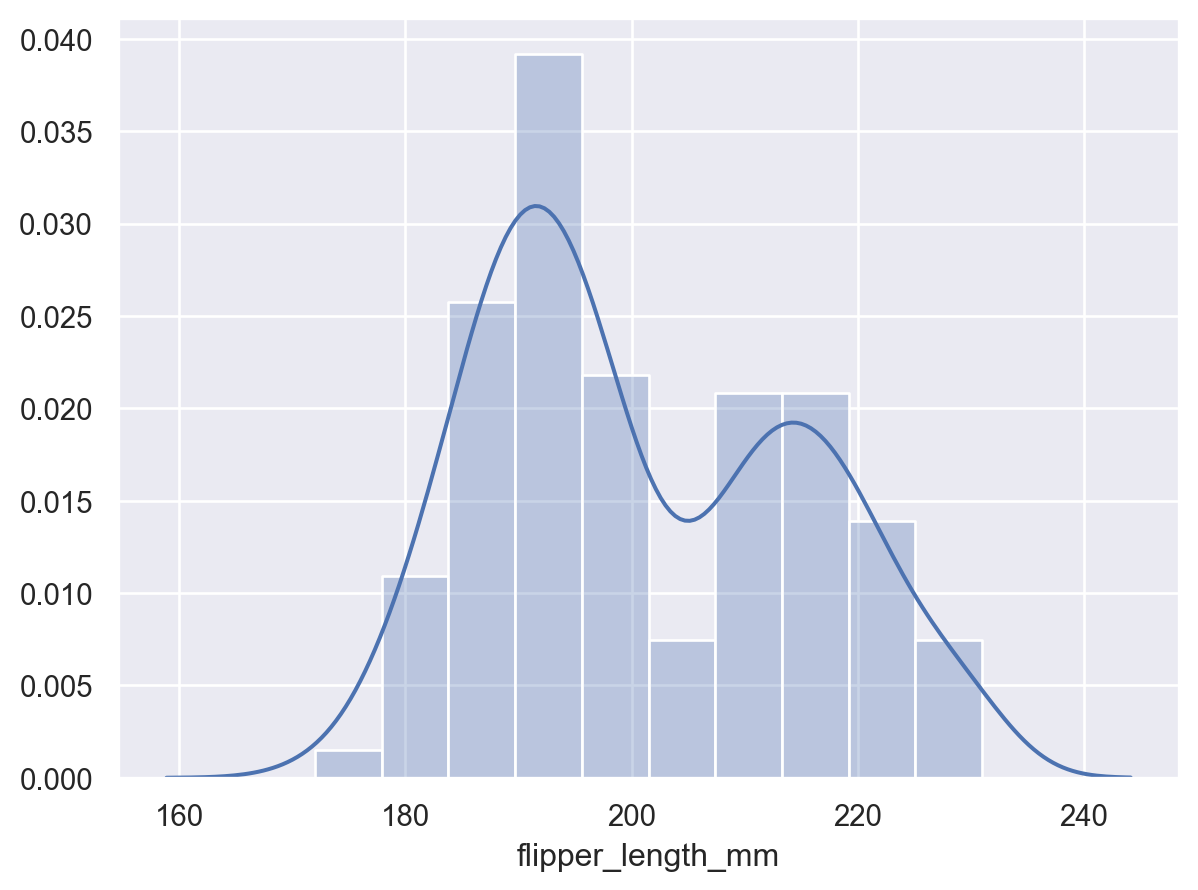
cutを使用して、観測値に対する密度曲線の範囲を制御しますp2.add(so.Line(), so.KDE(cut=0))

観測値が
y変数に割り当てられている場合、xの密度が表示されますso.Plot(penguins, y="flipper_length_mm").add(so.Area(), so.KDE())

gridsizeを使用して、密度が評価されるグリッドの解像度を増減しますp.add(so.Dots(), so.KDE(gridsize=100))
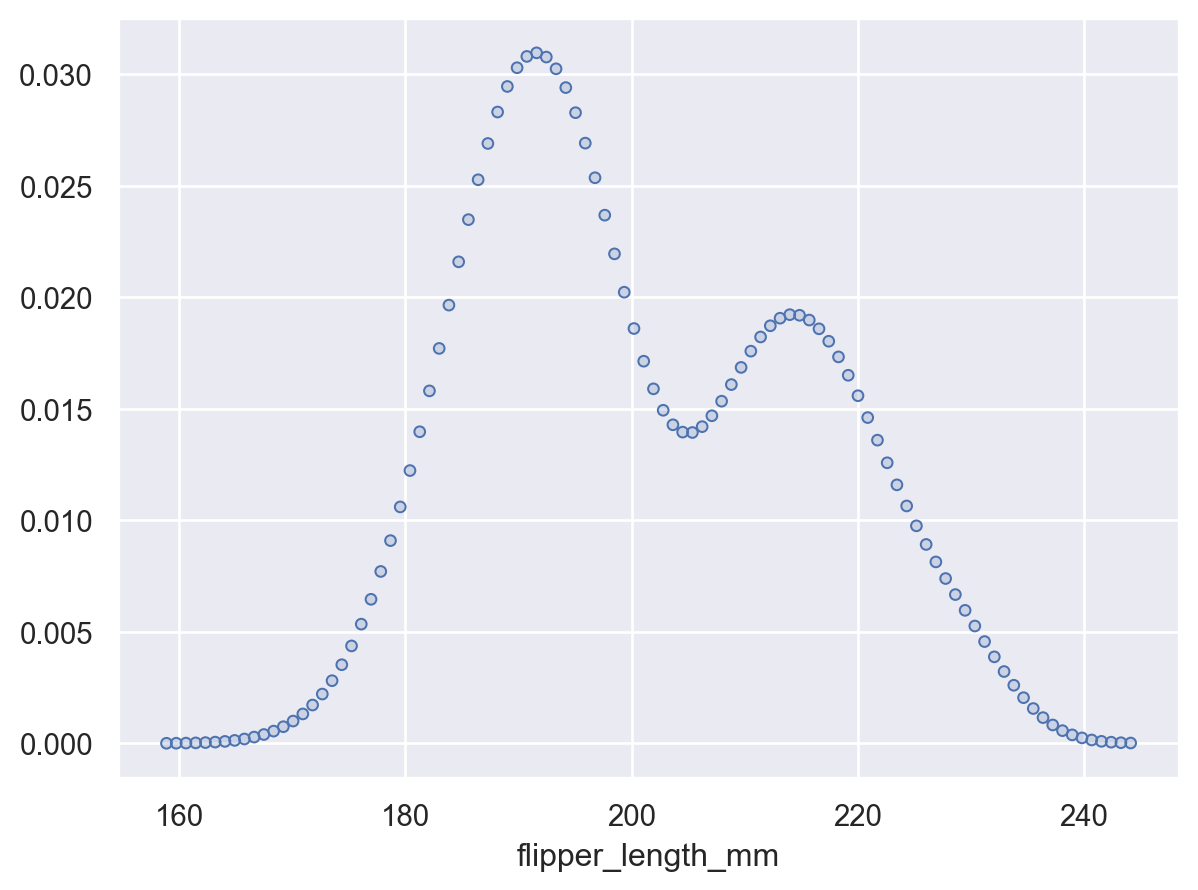
または、
Noneを渡して元のデータポイントで密度を評価しますp.add(so.Dots(), so.KDE(gridsize=None))

他の変数は推定のグループを定義します
p.add(so.Area(), so.KDE(), color="species")

デフォルトでは、密度はすべてのグループで正規化されます(つまり、結合密度が表示されます)。
common_norm=Falseを渡して条件付き密度を表示しますp.add(so.Area(), so.KDE(common_norm=False), color="species")

または、条件とする変数のリストを渡します
( p.facet("sex") .add(so.Area(), so.KDE(common_norm=["col"]), color="species") )

この統計量は、
Stack(common_grid=Trueの場合)などの他の変換と組み合わせることができますp.add(so.Area(), so.KDE(), so.Stack(), color="sex")

cumulative=Trueを設定して密度を積分しますp.add(so.Line(), so.KDE(cumulative=True))
