統計的関係の視覚化#
統計分析とは、データセット内の変数が互いにどのように関連し、それらの関係が他の変数にどのように依存するかを理解するプロセスです。データが適切に視覚化されると、人間の視覚システムは関係を示す傾向やパターンを見ることができるため、視覚化はこのプロセスの重要な構成要素となり得ます。
このチュートリアルでは、3つのseaborn関数を説明します。最も使用する関数はrelplot()です。これは、2つの一般的なアプローチ(散布図と線グラフ)を使用して統計的関係を視覚化するための図レベル関数です。relplot()は、2つの軸レベル関数のいずれかとFacetGridを組み合わせます。
scatterplot()(kind="scatter"付き;デフォルト)lineplot()(kind="line"付き)
後述するように、これらの関数は、シンプルで分かりやすいデータ表現を使用して、複雑なデータセット構造を表現できるため、非常に有益です。これらの関数は、色相、サイズ、スタイルのセマンティクスを使用して最大3つの追加変数をマッピングすることで拡張できる2次元グラフィックをプロットするため、このようなことが可能です。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="darkgrid")
散布図による変数の関連付け#
散布図は統計的視覚化の主要な手法です。各点がデータセット内の観測値を表す点のクラウドを使用して、2つの変数の同時分布を示します。この表現により、目視で、2つの変数の間に意味のある関係があるかどうかについての多くの情報を推測できます。
seabornでは、散布図を描くためのいくつかの方法があります。両方の変数が数値の場合に使用する最も基本的な方法は、scatterplot()関数です。カテゴリ視覚化チュートリアルでは、散布図を使用してカテゴリデータを視覚化するための特殊なツールを紹介します。scatterplot()はrelplot()におけるデフォルトのkindです(kind="scatter"を設定して強制することもできます)。
tips = sns.load_dataset("tips")
sns.relplot(data=tips, x="total_bill", y="tip")
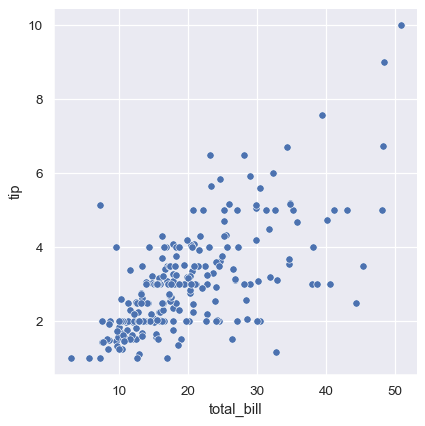
点は2次元でプロットされますが、3番目の変数に従って点を色付けすることで、プロットに別の次元を追加できます。seabornでは、これは「色相セマンティクス」の使用と呼ばれ、点の色に意味が加わります。
sns.relplot(data=tips, x="total_bill", y="tip", hue="smoker")
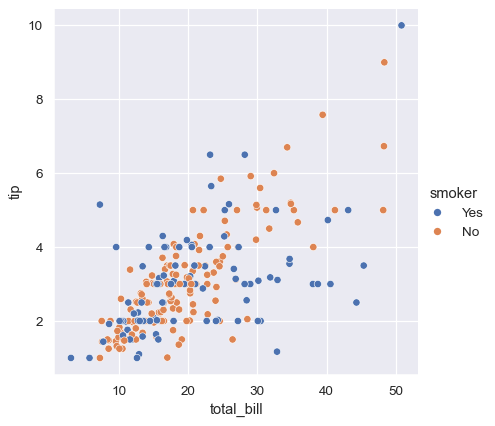
クラス間の違いを強調し、アクセシビリティを向上させるために、各クラスに異なるマーカースタイルを使用できます。
sns.relplot(
data=tips,
x="total_bill", y="tip", hue="smoker", style="smoker"
)
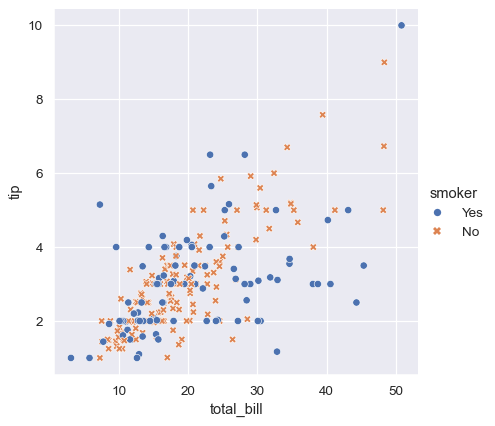
色相とスタイルをそれぞれ独立して変更することで、4つの変数を表現することも可能です。しかし、目は色よりも形に感度が低いため、注意深く行う必要があります。
sns.relplot(
data=tips,
x="total_bill", y="tip", hue="smoker", style="time",
)
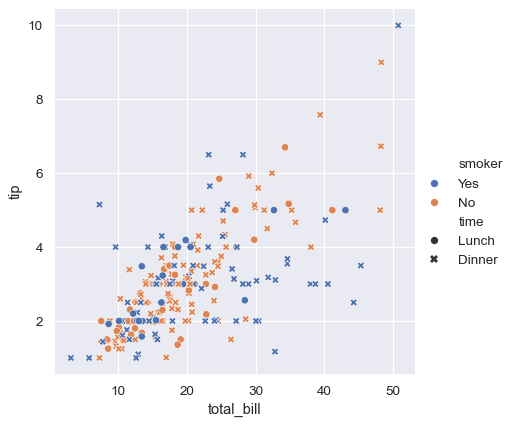
上記の例では、色相セマンティクスはカテゴリ型であったため、デフォルトの定性パレットが適用されました。色相セマンティクスが数値型の場合(具体的には、floatにキャストできる場合)、デフォルトの色付けは連続パレットに切り替わります。
sns.relplot(
data=tips, x="total_bill", y="tip", hue="size",
)
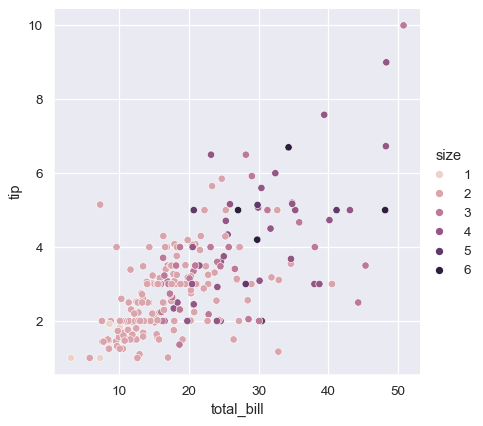
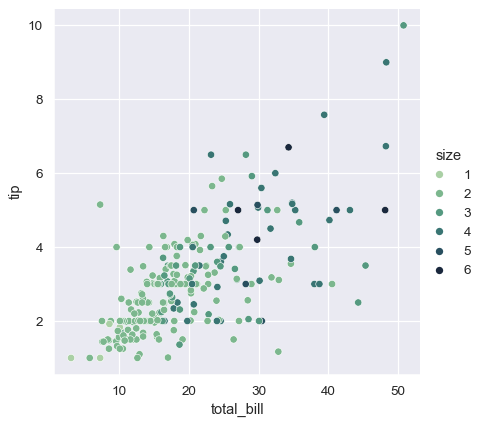
どちらの場合も、カラーパレットをカスタマイズできます。そのためには多くのオプションがあります。ここでは、cubehelix_palette()への文字列インターフェースを使用して、連続パレットをカスタマイズします。
sns.relplot(
data=tips,
x="total_bill", y="tip",
hue="size", palette="ch:r=-.5,l=.75"
)
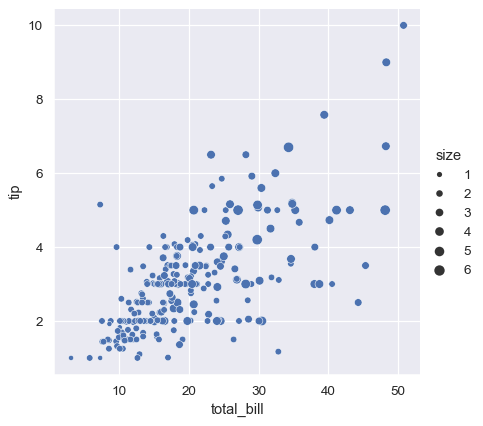
3番目のセマンティック変数は、各点のサイズを変更します。
sns.relplot(data=tips, x="total_bill", y="tip", size="size")
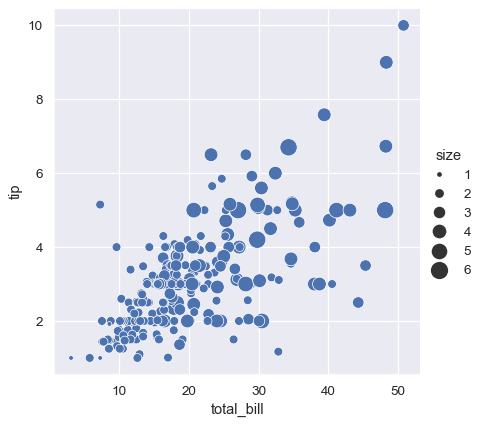
matplotlib.pyplot.scatter()とは異なり、変数のリテラル値は点の面積を選択するために使用されません。代わりに、データ単位の値の範囲は、面積単位の範囲に正規化されます。この範囲はカスタマイズできます。
sns.relplot(
data=tips, x="total_bill", y="tip",
size="size", sizes=(15, 200)
)
さまざまなセマンティクスを使用して統計的関係を示す方法をカスタマイズするための詳細な例は、scatterplot()のAPIの例で示されています。
線グラフによる連続性の強調#
散布図は非常に効果的ですが、普遍的に最適な視覚化の種類はありません。代わりに、視覚表現は、データセットの特性と、プロットで回答しようとしている質問に合わせて調整する必要があります。
データセットによっては、時間の関数として、または同様に連続的な変数として、ある変数の変化を理解したい場合があります。このような状況では、線グラフを描くのが良い選択です。seabornでは、lineplot()関数を使用して直接、またはkind="line"を設定したrelplot()関数を使用してこれを実現できます。
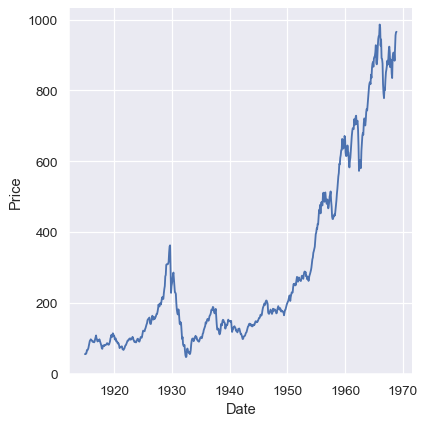
dowjones = sns.load_dataset("dowjones")
sns.relplot(data=dowjones, x="Date", y="Price", kind="line")
集約と不確実性の表現#
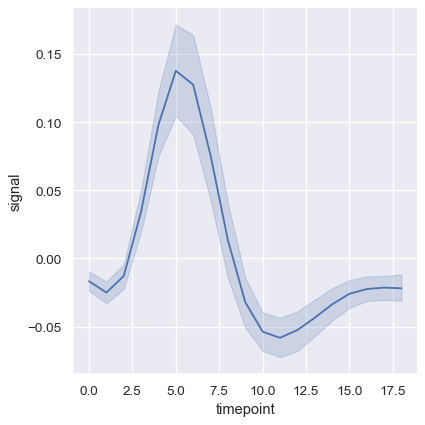
より複雑なデータセットでは、同じx変数の値に対して複数の測定値があります。seabornのデフォルトの動作は、平均と平均を中心とした95%信頼区間をプロットすることで、各x値における複数の測定値を集約することです。
fmri = sns.load_dataset("fmri")
sns.relplot(data=fmri, x="timepoint", y="signal", kind="line")
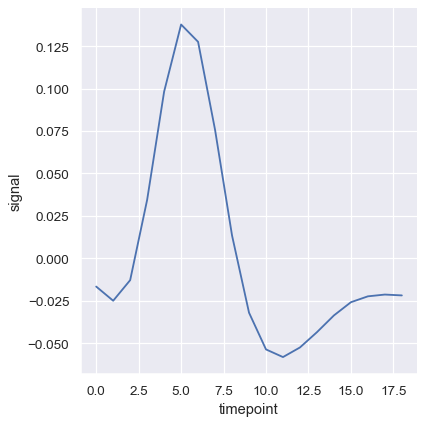
信頼区間はブートストラップを使用して計算されますが、大規模なデータセットでは時間のかかる処理になる可能性があります。したがって、それらを無効にすることも可能です。
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", errorbar=None,
)
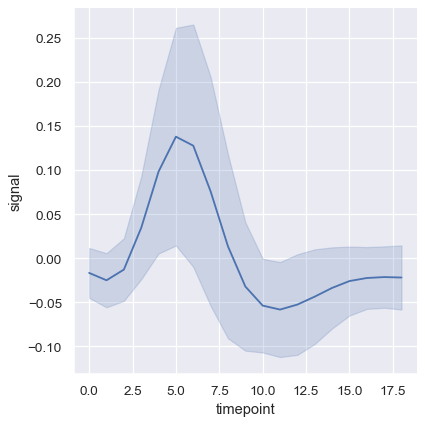
特に大規模なデータでは、信頼区間ではなく標準偏差をプロットすることで、各時点における分布の広がりを表すことも良い選択肢です。
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", errorbar="sd",
)
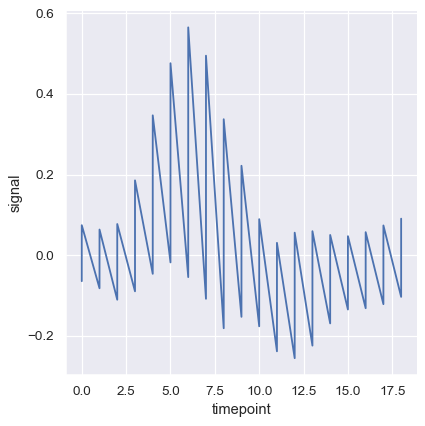
集約を完全にオフにするには、estimatorパラメーターをNoneに設定します。データが各点で複数の観測値を持つ場合、これは奇妙な効果を生む可能性があります。
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal",
estimator=None,
)
セマンティックマッピングによるデータの部分集合のプロット#
lineplot()関数は、scatterplot()と同様に柔軟性があります。プロット要素の色相、サイズ、スタイルを変更することで、最大3つの追加変数を表示できます。scatterplot()と同じAPIを使用するため、matplotlibで線と点の外観を制御するパラメーターについて考える必要はありません。
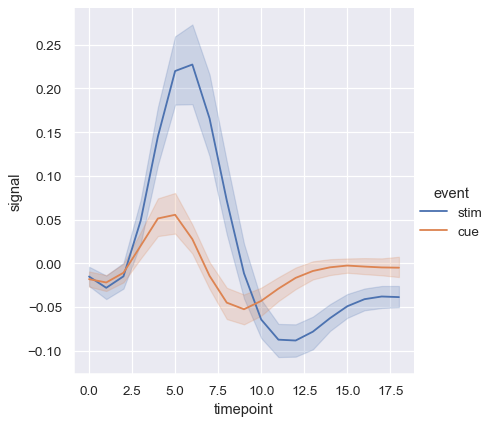
lineplot()でセマンティクスを使用すると、データの集約方法も決定されます。たとえば、2つのレベルの色相セマンティクスを追加すると、プロットが2本の線と誤差帯に分割され、それぞれの色で対応するデータの部分集合を示します。
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", hue="event",
)
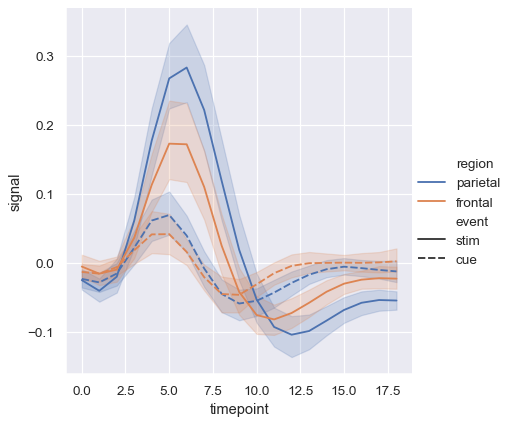
線グラフにスタイルセマンティクスを追加すると、デフォルトで線の破線のパターンが変更されます。
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal",
hue="region", style="event",
)
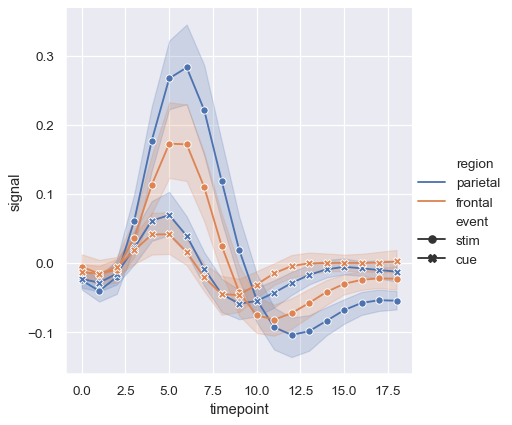
しかし、破線と共に、またはその代わりに、各観測値で使用されるマーカーによって部分集合を識別することもできます。
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", hue="region", style="event",
dashes=False, markers=True,
)
散布図と同様に、複数の意味論を用いて折れ線グラフを作成する際には注意が必要です。情報が得られる場合もありますが、解析や解釈が困難になることもあります。しかし、追加の変数を1つだけ検討する場合でも、線のカラーとスタイルの両方を変更すると便利です。これにより、白黒で印刷した場合や色覚異常のある人が閲覧する場合でも、グラフのアクセシビリティが向上します。
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", hue="event", style="event",
)
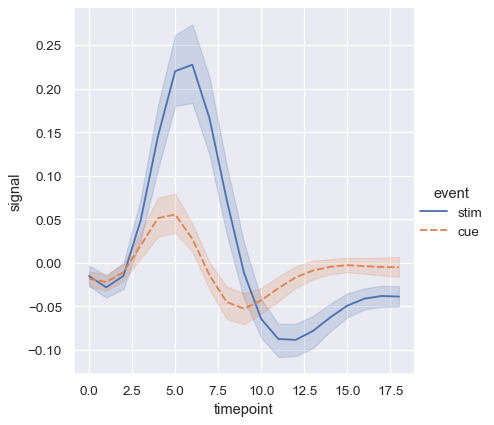
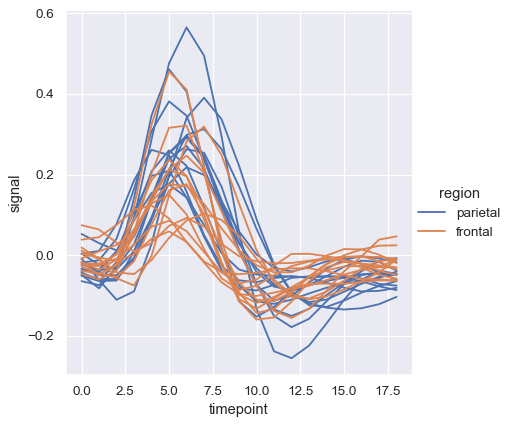
反復測定データ(つまり、複数回サンプリングされた単位を持つデータ)を扱う場合は、意味論で区別することなく、各サンプリング単位を個別にプロットすることもできます。これにより、凡例が煩雑になるのを避けることができます。
sns.relplot(
data=fmri.query("event == 'stim'"), kind="line",
x="timepoint", y="signal", hue="region",
units="subject", estimator=None,
)
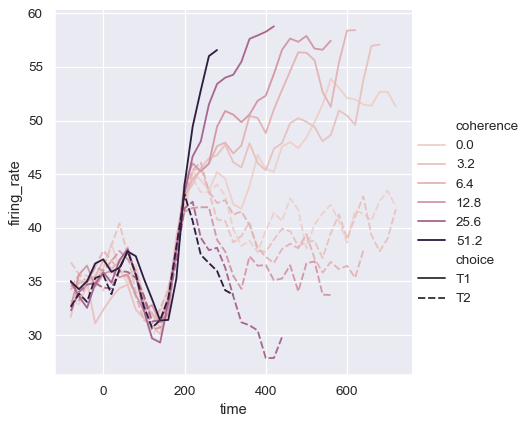
lineplot()におけるデフォルトのカラーマップと凡例の処理は、hueの意味論がカテゴリカルか数値かによっても異なります。
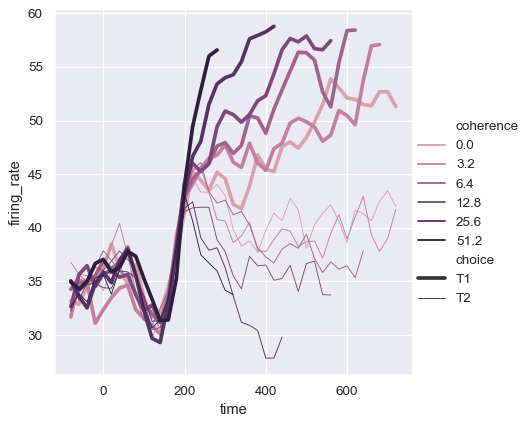
dots = sns.load_dataset("dots").query("align == 'dots'")
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate",
hue="coherence", style="choice",
)
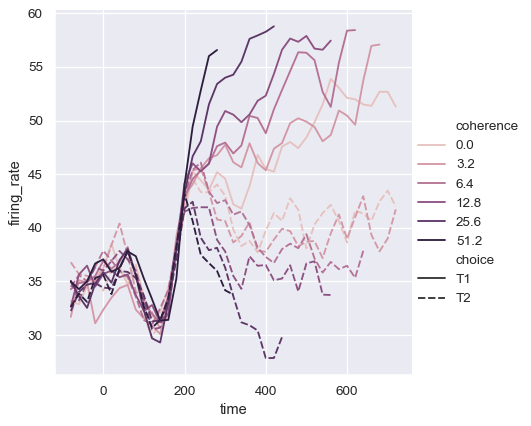
hue変数が数値であっても、線形カラースケールではうまく表現されない場合があります。これは、hue変数のレベルが対数スケールで表されている場合に該当します。リストまたは辞書を渡すことで、各線に特定の色値を指定できます。
palette = sns.cubehelix_palette(light=.8, n_colors=6)
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate",
hue="coherence", style="choice", palette=palette,
)
または、カラーマップの正規化方法を変更することもできます。
from matplotlib.colors import LogNorm
palette = sns.cubehelix_palette(light=.7, n_colors=6)
sns.relplot(
data=dots.query("coherence > 0"), kind="line",
x="time", y="firing_rate",
hue="coherence", style="choice",
hue_norm=LogNorm(),
)
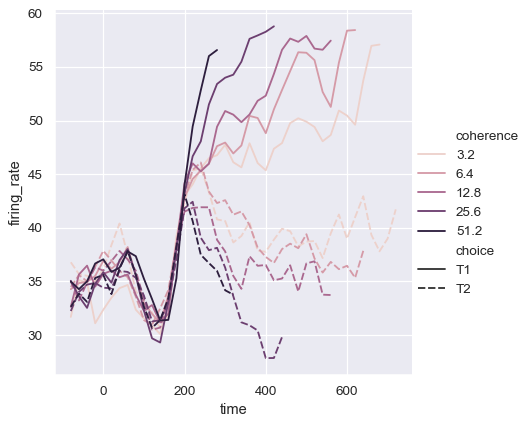
3番目の意味論であるsizeは、線の太さを変更します。
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate",
size="coherence", style="choice",
)
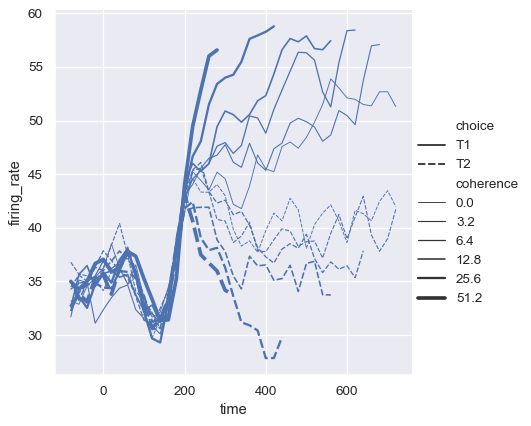
size変数は通常数値ですが、線の太さにカテゴリ変数をマッピングすることも可能です。「太い」対「細い」線以上の区別は困難になるため、注意が必要です。ただし、線が頻繁に変動する場合、破線は認識しにくいため、そのような場合は幅を変える方が効果的です。
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate",
hue="coherence", size="choice", palette=palette,
)
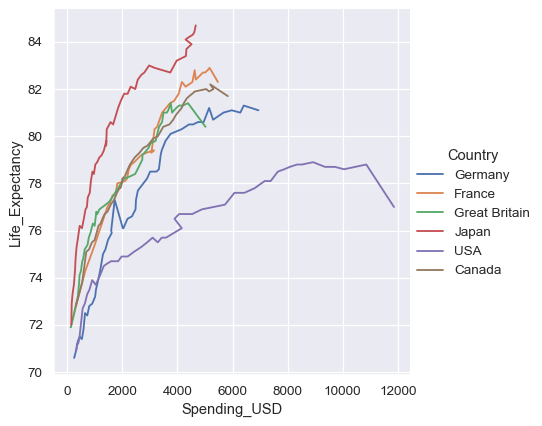
ソートと方向の制御#
lineplot()は、多くの場合yをxの関数として描画しようとしていると仮定しているため、デフォルトの動作ではプロット前にx値でデータをソートします。ただし、これは無効にすることができます。
healthexp = sns.load_dataset("healthexp").sort_values("Year")
sns.relplot(
data=healthexp, kind="line",
x="Spending_USD", y="Life_Expectancy", hue="Country",
sort=False
)
y軸に沿ってソート(および集計)することも可能です。
sns.relplot(
data=fmri, kind="line",
x="signal", y="timepoint", hue="event",
orient="y",
)
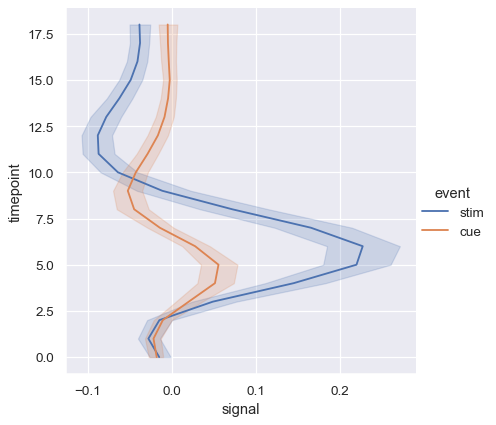
ファセットによる複数の関係性の表示#
このチュートリアルでは、これらの関数は複数の意味変数を同時に表示できますが、常にそれが効果的とは限らないことを強調しました。しかし、2つの変数の間の関係が、それ以外の1つ以上の変数にどのように依存しているかを理解したい場合はどうでしょうか?
最適なアプローチは、複数のプロットを作成することです。relplot()はFacetGridに基づいているため、これは簡単に行えます。追加の変数の影響を示すには、それをプロットの意味役割の1つに割り当てる代わりに、それを視覚化を「ファセット」するために使用します。つまり、複数の軸を作成し、データのサブセットをそれぞれにプロットします。
sns.relplot(
data=tips,
x="total_bill", y="tip", hue="smoker", col="time",
)
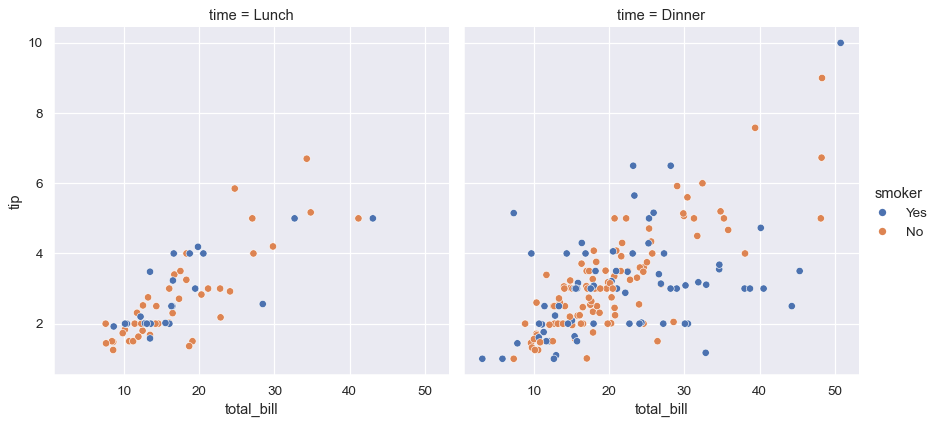
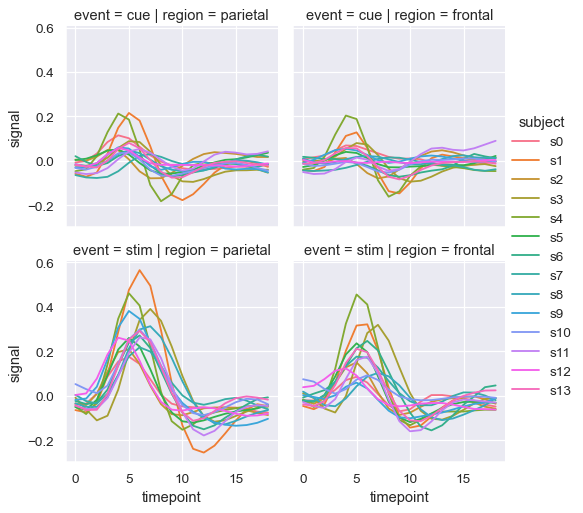
列でファセット化し、行でファセット化することで、2つの変数の影響を同時に示すこともできます。グリッドに追加する変数が増えるにつれて、図のサイズを小さくすることを検討する必要があるかもしれません。FacetGridのサイズは、各ファセットの高さおよびアスペクト比によってパラメータ化されていることに注意してください。
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", hue="subject",
col="region", row="event", height=3,
estimator=None
)
変数の多くのレベルにわたる効果を調べたい場合は、その変数を列でファセット化し、ファセットを行に「ラップ」すると良いでしょう。
sns.relplot(
data=fmri.query("region == 'frontal'"), kind="line",
x="timepoint", y="signal", hue="event", style="event",
col="subject", col_wrap=5,
height=3, aspect=.75, linewidth=2.5,
)
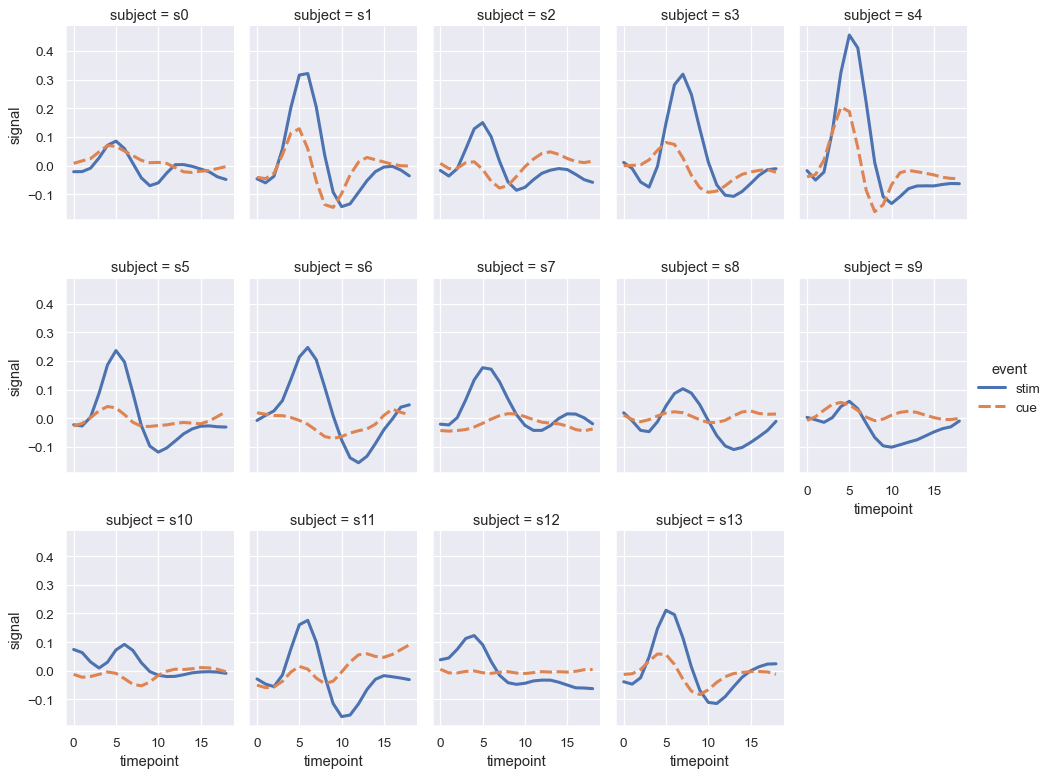
これらの視覚化は、場合によっては「格子状」プロットまたは「スモールマルチプル」と呼ばれ、全体的なパターンとそれらからのずれを簡単に検出できる形式でデータを提示するため、非常に効果的です。scatterplot()およびrelplot()が提供する柔軟性を活用する必要がありますが、常に、いくつかの単純なプロットの方が1つの複雑なプロットよりも通常は効果的であることを念頭に置いてください。