カテゴリデータの可視化#
関係プロットのチュートリアルでは、異なる視覚表現を使用して、データセット内の複数の変数間の関係を示す方法を説明しました。例では、主な関係が2つの数値変数間のケースに焦点を当てました。主要な変数の1つが「カテゴリ」(離散グループに分割)である場合、より特殊な可視化アプローチを使用すると役立つ場合があります。
seabornには、カテゴリデータを含む関係を可視化するいくつかの異なる方法があります。relplot()とscatterplot()またはlineplot()の関係と同様に、これらのプロットを作成するには2つの方法があります。カテゴリデータをさまざまな方法でプロットするための軸レベル関数が多数あり、それらへの統一された高レベルアクセスを提供する図レベルインターフェースであるcatplot()があります。
異なるカテゴリプロットの種類を3つの異なるファミリに属するものと考えると便利です。以下で詳しく説明します。
カテゴリ散布図
stripplot()(kind="strip"を使用; デフォルト)swarmplot()(kind="swarm"を使用)
カテゴリ分布プロット
boxplot()(kind="box"を使用)violinplot()(kind="violin"を使用)boxenplot()(kind="boxen"を使用)
カテゴリ推定プロット
pointplot()(kind="point"を使用)barplot()(kind="bar"を使用)countplot()(kind="count"を使用)
これらのファミリは、異なるレベルの粒度を使用してデータを表します。どれを使用するかを決定する際には、回答したい質問について考える必要があります。統一APIを使用すると、さまざまな種類を簡単に切り替えて、さまざまな視点からデータを確認できます。
このチュートリアルでは、主に図レベルインターフェースであるcatplot()に焦点を当てます。この関数は上記の各関数の高レベルインターフェースであるため、各種類のプロットを表示する際にそれらを参照し、より詳細な種類固有のAPIドキュメントを手元に置いておきます。
カテゴリ散布図#
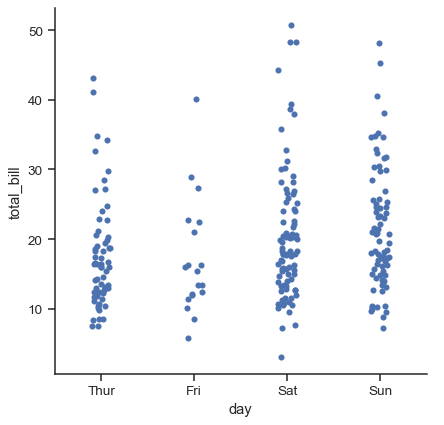
catplot()のデータのデフォルト表現は散布図を使用します。 seabornには実際には2つの異なるカテゴリ散布図があります。それらは、カテゴリデータを散布図で表現する際の主な課題、つまり1つのカテゴリに属するすべての点がカテゴリ変数に対応する軸に沿って同じ位置に配置されるという課題を解決するために、異なるアプローチを取ります。catplot()のデフォルトの「kind」であるstripplot()で使用されるアプローチは、カテゴリ軸上の点の位置を少量のランダムな「ジッター」で調整することです。
tips = sns.load_dataset("tips")
sns.catplot(data=tips, x="day", y="total_bill")
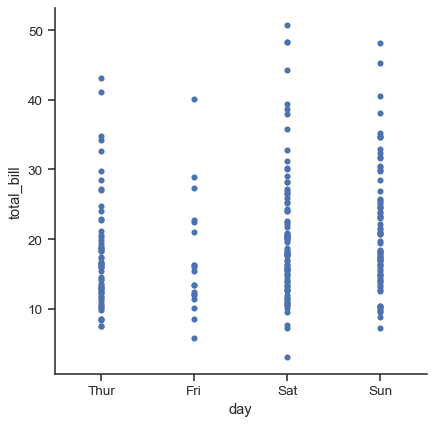
jitterパラメータは、ジッターの大きさを制御するか、完全に無効にします。
sns.catplot(data=tips, x="day", y="total_bill", jitter=False)
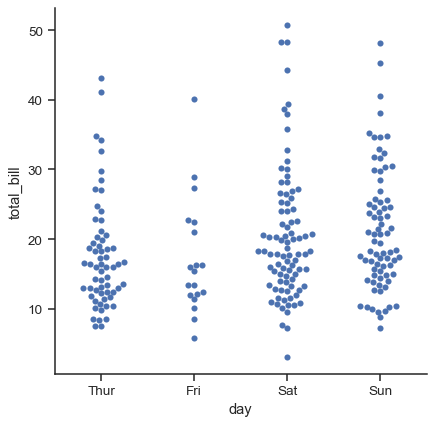
2番目のアプローチは、点が重ならないようにするアルゴリズムを使用して、カテゴリ軸に沿って点を調整します。観測値の分布をより適切に表現できますが、比較的小さなデータセットにのみ有効です。この種のプロットは「ビースウォーム」と呼ばれることもあり、catplot()でkind="swarm"を設定することによってアクティブ化されるswarmplot()によってseabornで描画されます。
sns.catplot(data=tips, x="day", y="total_bill", kind="swarm")
関係プロットと同様に、hueセマンティクスを使用して、カテゴリプロットに別の次元を追加することが可能です。(カテゴリプロットは現在、sizeまたはstyleセマンティクスをサポートしていません)。各カテゴリプロット関数は、hueセマンティクスを異なる方法で処理します。散布図の場合、点の色を変更するだけで済みます。
sns.catplot(data=tips, x="day", y="total_bill", hue="sex", kind="swarm")
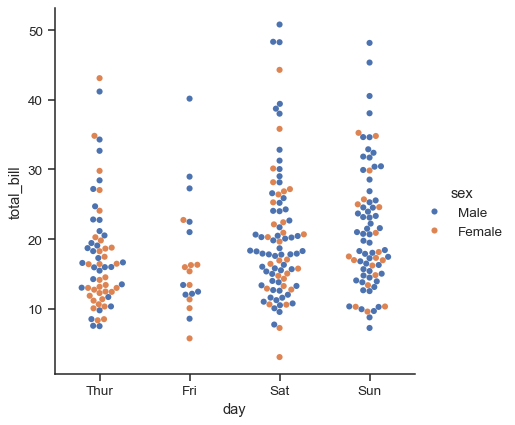
数値データとは異なり、カテゴリ変数のレベルを軸に沿ってどのように順序付けるかは必ずしも明確ではありません。一般に、seabornカテゴリプロット関数は、データからカテゴリの順序を推測しようとします。データにpandas Categoricalデータ型がある場合、カテゴリのデフォルトの順序をそこで設定できます。カテゴリ軸に渡された変数が数値に見える場合、レベルはソートされます。ただし、デフォルトでは、データは依然としてカテゴリとして扱われ、数値を使用してラベル付けされている場合でも、カテゴリ軸上の序数位置(具体的には0、1、…)に描画されます。
sns.catplot(data=tips.query("size != 3"), x="size", y="total_bill")
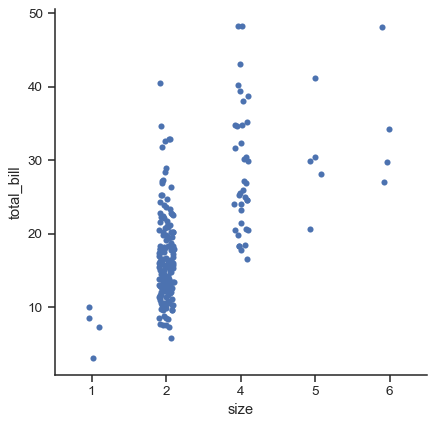
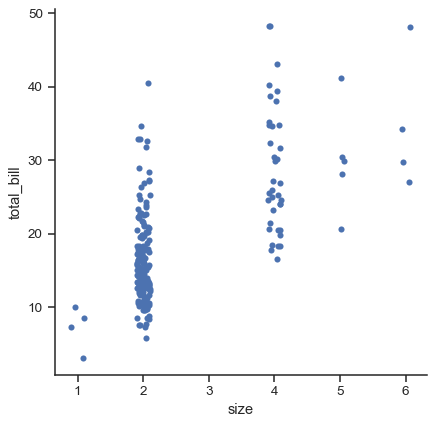
v0.13.0以降、すべてのカテゴリプロット関数にはnative_scaleパラメータがあり、基になるデータプロパティを変更せずに数値または日時データ をカテゴリグループ化に使用する場合にTrueに設定できます。
sns.catplot(data=tips.query("size != 3"), x="size", y="total_bill", native_scale=True)
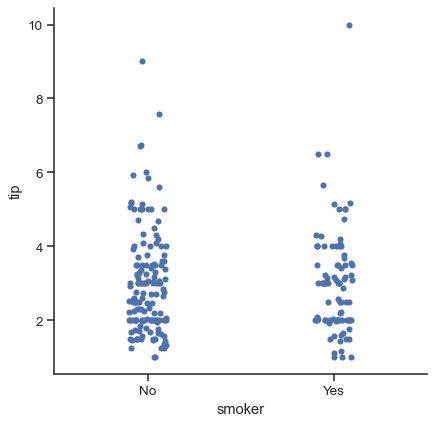
デフォルトの順序を選択するもう1つのオプションは、データセットに表示されるカテゴリのレベルを取得することです。orderパラメータを使用して、プロットごとに順序を制御することもできます。これは、同じ図に複数のカテゴリプロットを描画する場合に重要になる可能性があり、以下で詳しく説明します。
sns.catplot(data=tips, x="smoker", y="tip", order=["No", "Yes"])
「カテゴリ軸」の概念について触れました。これらの例では、それは常に水平軸に対応していました。ただし、カテゴリ変数を垂直軸に配置すると便利なことがよくあります(特に、カテゴリ名が比較的長い場合やカテゴリが多い場合)。これを行うには、変数の軸への割り当てを交換します。
sns.catplot(data=tips, x="total_bill", y="day", hue="time", kind="swarm")
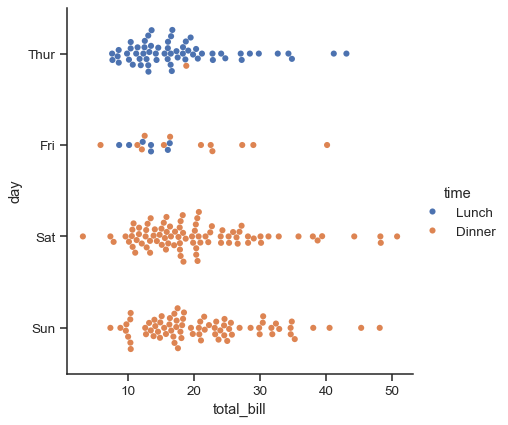
分布の比較#
データセットのサイズが大きくなるにつれて、カテゴリ散布図は、各カテゴリ内の値の分布に関する情報を提供する上で制限されます。この場合、カテゴリレベル全体で簡単に比較できるように、分布情報を要約するためのいくつかのアプローチがあります。
箱ひげ図#
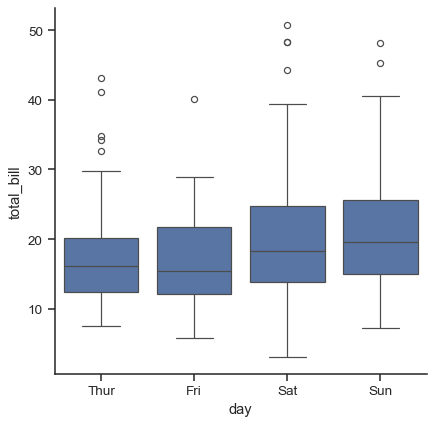
1つ目は、おなじみのboxplot()です。この種のプロットは、分布の3つの四分位値と極値を示しています。「ひげ」は、下位四分位数と上位四分位数の1.5 IQR以内にある点まで伸び、この範囲外にある観測値は個別に表示されます。つまり、箱ひげ図の各値は、データの実際の観測値に対応しています。
sns.catplot(data=tips, x="day", y="total_bill", kind="box")
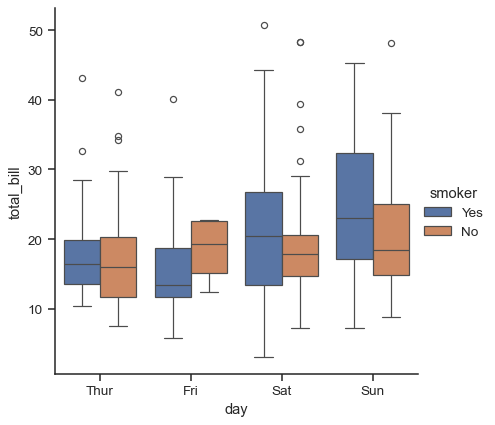
hueセマンティクスを追加する場合、セマンティック変数の各レベルのボックスは狭くなり、カテゴリ軸に沿ってシフトされます。
sns.catplot(data=tips, x="day", y="total_bill", hue="smoker", kind="box")
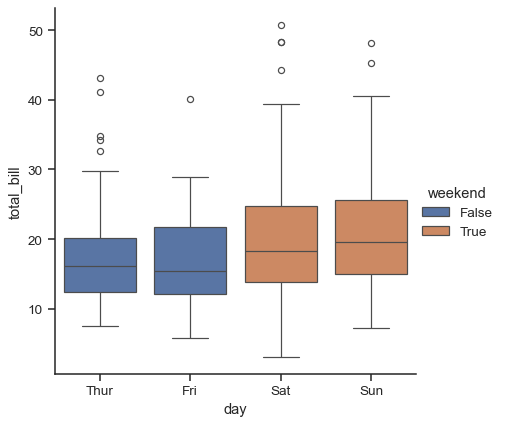
この動作は「ドッジング」と呼ばれ、dodgeパラメータによって制御されます。デフォルトでは(v0.13.0以降)、要素は重ならない場合にのみドッジします。
tips["weekend"] = tips["day"].isin(["Sat", "Sun"])
sns.catplot(data=tips, x="day", y="total_bill", hue="weekend", kind="box")
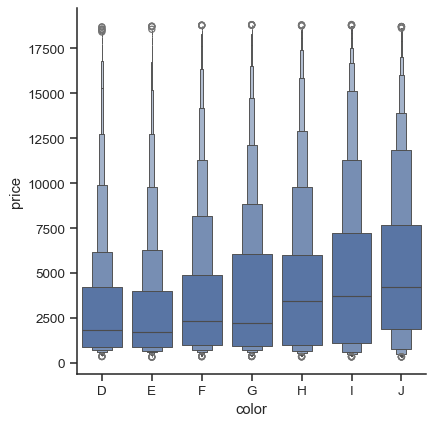
関連関数であるboxenplot()は、箱ひげ図に似ていますが、分布の形状に関する詳細情報を表示するために最適化されたプロットを描画します。大規模なデータセットに最適です。
diamonds = sns.load_dataset("diamonds")
sns.catplot(
data=diamonds.sort_values("color"),
x="color", y="price", kind="boxen",
)
バイオリンプロット#
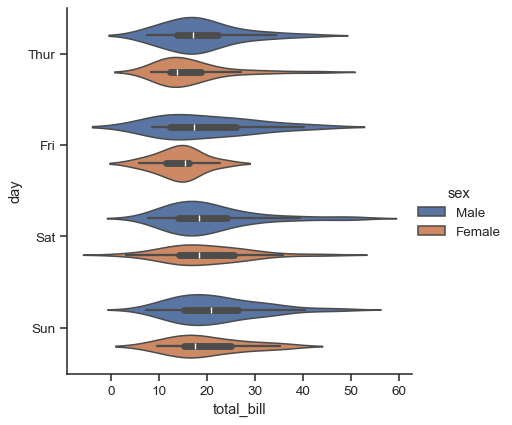
別のアプローチは、分布チュートリアルで説明されているカーネル密度推定手順と箱ひげ図を組み合わせたviolinplot()です。
sns.catplot(
data=tips, x="total_bill", y="day", hue="sex", kind="violin",
)
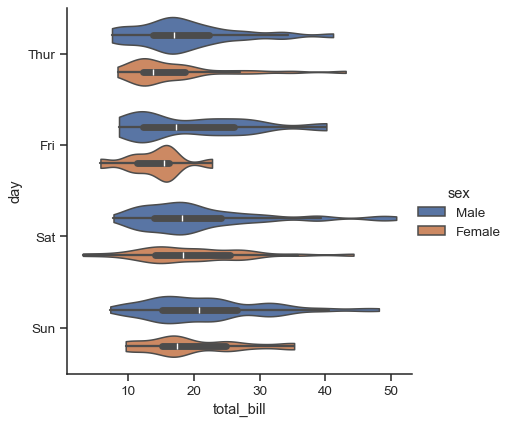
このアプローチでは、カーネル密度推定値を使用して、値の分布をより豊かに記述します。さらに、箱ひげ図の四分位数とひげの値がバイオリン内に表示されます。欠点は、violinplotはKDEを使用するため、微調整が必要になる可能性のある他のパラメータがいくつかあり、単純な箱ひげ図に比べて複雑さが増すことです。
sns.catplot(
data=tips, x="total_bill", y="day", hue="sex",
kind="violin", bw_adjust=.5, cut=0,
)
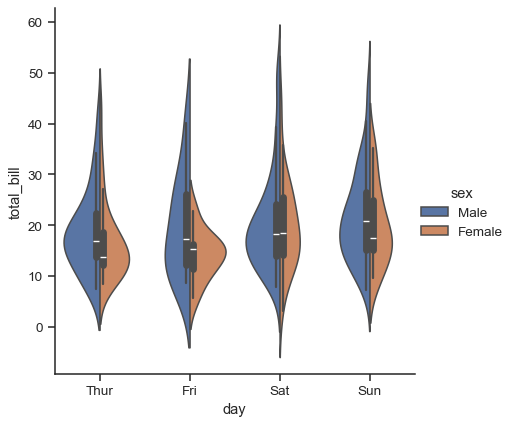
バイオリンを「分割」することもでき、スペースをより効率的に使用できます。
sns.catplot(
data=tips, x="day", y="total_bill", hue="sex",
kind="violin", split=True,
)
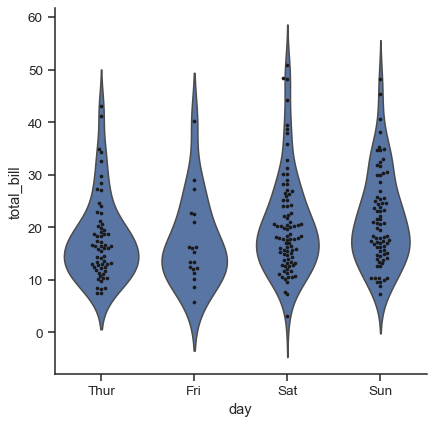
最後に、バイオリンの内部に描画されるプロットには、要約箱ひげ図の値の代わりに個々の観測値を表示する方法など、いくつかのオプションがあります。
sns.catplot(
data=tips, x="day", y="total_bill", hue="sex",
kind="violin", inner="stick", split=True, palette="pastel",
)
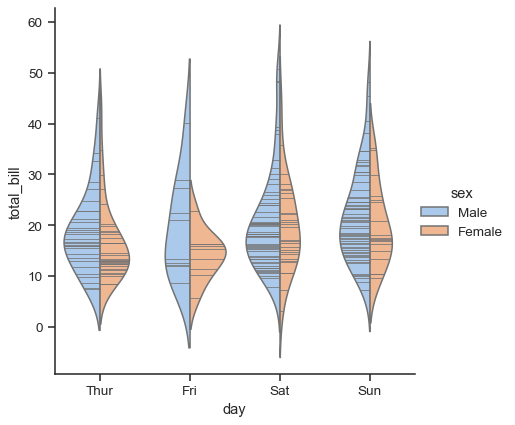
また、swarmplot() または stripplot() を箱ひげ図またはバイオリンプロットと組み合わせて、分布の概要とともに各観測値を表示することも役立ちます。
g = sns.catplot(data=tips, x="day", y="total_bill", kind="violin", inner=None)
sns.swarmplot(data=tips, x="day", y="total_bill", color="k", size=3, ax=g.ax)
中心傾向の推定#
他の用途では、各カテゴリ内の分布を表示するのではなく、値の中心傾向の推定値を表示したい場合があります。Seaborn にはこの情報を表示する 2 つの主要な方法があります。重要なのは、これらの関数の基本的な API が、上記で説明したものと同じであることです。
棒グラフ#
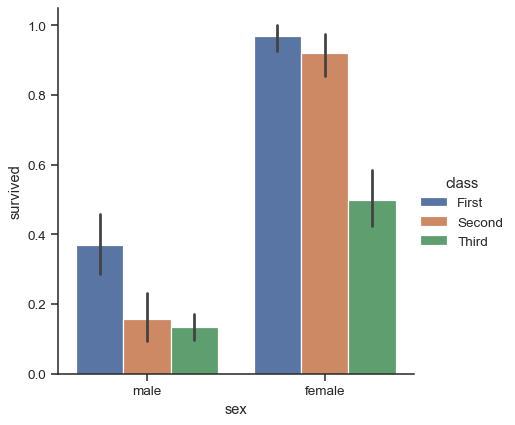
この目標を達成する一般的なスタイルのプロットは棒グラフです。Seaborn では、barplot() 関数はデータセット全体を操作し、関数を適用して推定値を取得します(デフォルトでは平均を取得します)。各カテゴリに複数の観測値がある場合、ブートストラップを使用して推定値の周りの信頼区間を計算し、エラーバーを使用してプロットします。
titanic = sns.load_dataset("titanic")
sns.catplot(data=titanic, x="sex", y="survived", hue="class", kind="bar")
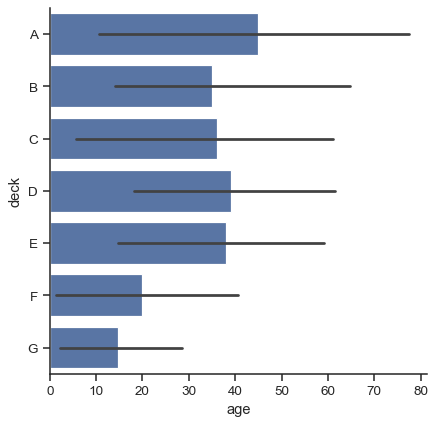
デフォルトのエラーバーは 95% 信頼区間を示していますが(v0.12 以降)、他の多くの表現から選択することが可能です。
sns.catplot(data=titanic, x="age", y="deck", errorbar=("pi", 95), kind="bar")
棒グラフの特殊なケースは、2 番目の変数の統計量を計算するのではなく、各カテゴリの観測値の数を表示する場合です。これは、量的変数ではなくカテゴリ変数のヒストグラムに似ています。Seaborn では、countplot() 関数を使用して簡単にこれを行うことができます。
sns.catplot(data=titanic, x="deck", kind="count")
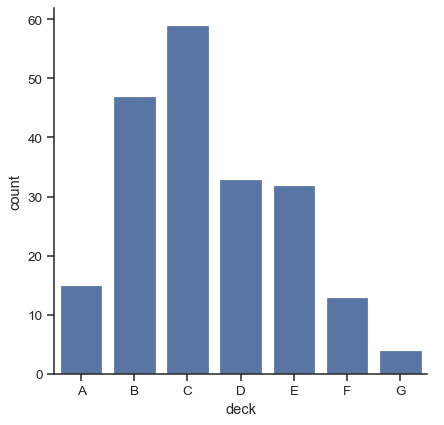
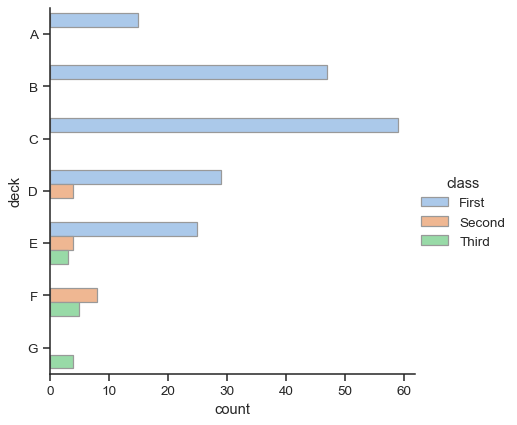
barplot() と countplot() はどちらも、上記で説明したすべてのオプションに加えて、各関数の詳細なドキュメントに示されている他のオプションを使用して呼び出すことができます。
sns.catplot(
data=titanic, y="deck", hue="class", kind="count",
palette="pastel", edgecolor=".6",
)
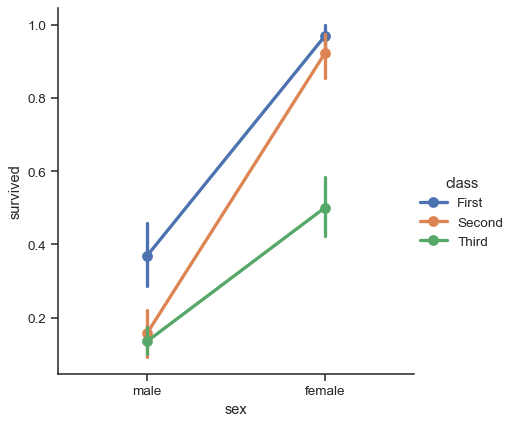
点プロット#
同じ情報を視覚化する別のスタイルは、pointplot() 関数によって提供されます。この関数も推定値をもう一方の軸の高さでエンコードしますが、完全なバーを表示するのではなく、点推定値と信頼区間をプロットします。さらに、pointplot() は同じ hue カテゴリの点を接続します。これにより、傾きの違いを認識するのが得意なため、主要な関係が色相セマンティックの関数としてどのように変化しているかを簡単に確認できます。
sns.catplot(data=titanic, x="sex", y="survived", hue="class", kind="point")
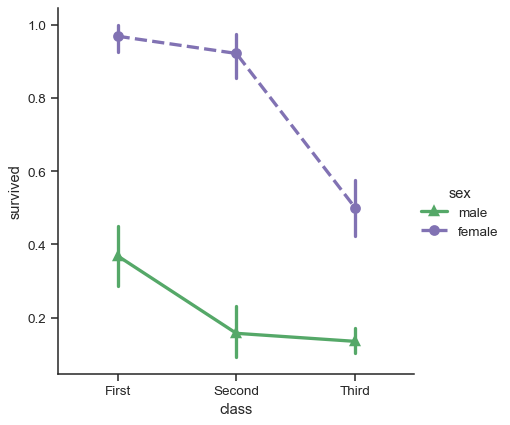
カテゴリ関数は関係関数の style セマンティックを欠いていますが、白黒で最大限にアクセス可能で再現性の高い図を作成するために、マーカーやラインスタイルを色相とともに変更することをお勧めします。
sns.catplot(
data=titanic, x="class", y="survived", hue="sex",
palette={"male": "g", "female": "m"},
markers=["^", "o"], linestyles=["-", "--"],
kind="point"
)
追加の次元の表示#
relplot() と同様に、catplot() が FacetGrid 上に構築されているという事実により、ファセット変数を簡単に追加して高次元の関係を視覚化できます。
sns.catplot(
data=tips, x="day", y="total_bill", hue="smoker",
kind="swarm", col="time", aspect=.7,
)
プロットをさらにカスタマイズするには、返される FacetGrid オブジェクトのメソッドを使用できます。
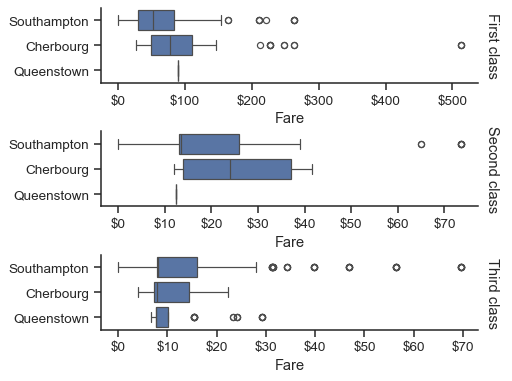
g = sns.catplot(
data=titanic,
x="fare", y="embark_town", row="class",
kind="box", orient="h",
sharex=False, margin_titles=True,
height=1.5, aspect=4,
)
g.set(xlabel="Fare", ylabel="")
g.set_titles(row_template="{row_name} class")
for ax in g.axes.flat:
ax.xaxis.set_major_formatter('${x:.0f}')